A response to "Did we market Knative wrong?"
What happened 😧 ?
Earlier today, my dear Twitter fellow Ahmet posted a blog post where he looks back at the beginning of the Knative project. In his point of view, he recaps on the mistakes that were made in the early days of the project, effectively hindering its adoption to become the de facto standard for simplifying (micro|nano) service deployments on Kubernetes.
Ahmet has been advocating and sharing knowledge around Knative for a long time. In fact, he got me into reevaluating Knative after I had ruled it out as the core engine when we created the VMware Event Broker Appliance (VEBA). I’ll come back to this at the end…
Having seen Ahmet sharing knowledge and opinions on the Knative project for several years, I truly believe the main intention behind this blog post is to raise more awareness for this great platform - while also clearing some FUD. In my opinion, his article provides a fair and balanced assessment of some key mistakes which, looking back, definitely hindered the adoption of Knative in the wider cloud-native communities.
So if I’m agreeing to what he said, why am I writing this response then you might ask? To be honest, when I saw the tweet this morning and read the post, my initial reaction was to respond in the tweet. But a tweet would have been too short and would also not have done full justice to the Knative community.
And since I have not been involved from the beginning, i.e. I don’t know all the internals and politics, I thought there’s probably not much to add to it. But then I saw this:
I am curious what @embano1 has to say about this article.
— ahmetb (@ahmetb) June 17, 2021
It does not happen every day (read: never 😂 ) that a highly respected Twitter fellow asks me for my opinion.
I truly believe that Knative has a bright future as it solves so many of my pain points in getting work done on the Kubernetes platform. I’m also fortunate to work with the brilliant minds and founders on a daily basis. Thus, over time I’ve become a contributor and advocate of the project, both internally at VMware and externally.
Instead of rehashing what Ahmet already wrote, I’m going to give you my personal Knative story: Why I initially scratched the project from using it in VEBA and some of the mistakes I think the Knative community has made from the perspective of an outsider (end-user). To be fair, it’s easy to point out mistakes and failures from the outside. So always remember:
(Albert Einstein)
A bit of History
When Amazon Web Services (AWS) announced Lambda, a fully-managed (“serverless”) compute service, back in 2014, my immediate reaction was that it could completely revolutionize the industry. But by the time I had a different role and focus and it was not before 2017 that I took a closer look at Lambda. And then it clicked.
A while ago I created this slide to show the parallel universes of how AWS Lambda and Kubernetes (and the cloud-native ecosystem in general) have evolved mostly in isolation. This is also true for the communities backing these technologies (and not too seldom fighting over THE right approach).
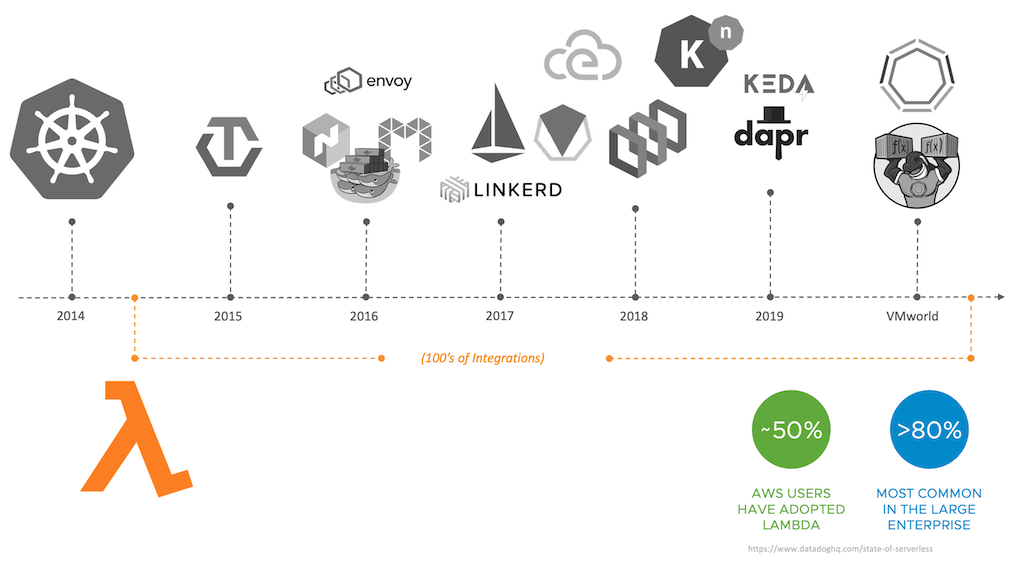
Due to the focus and hype (good and bad) around Kubernetes, it’s easy to miss the Lambda (and serverless) effect. Fast forward, Lambda and its serverless brothers and sisters on the AWS platform, have revolutionized the industry and the way we think about designing and running software1.
Not only did cloud giants like Google, Microsoft and Alibaba follow with similar managed services, the evolving serverless mindset also paved the way for the Knative project.
In an informal chat with one of the Knative co-founders, Ville told me that he was not happy with all the things you have to YAML-fy to deploy an app on Kubernetes. Focusing on the WHAT (to get done) vs. HOW (something is done internally) is resonating more than ever with the growing complexity of the toolset and business requirements around us.
Now you could argue that just by installing Knative you are definitely not serverless. Of course not! There’s more to “being serverless” (see links above). But with everything in life, things are nuanced and to me the path to serverless is an evolution…and certainly not the end goal either.
While Google and Microsoft might have invented “serverless” technology back in the early days of cloud computing with their PaaS offerings2, AWS met the customers where they are: infrastructure. And so did Kubernetes later.
AWS certainly leap-frogged their competition with Lambda. But the cloud giant was also “forced” to respond to the needs of their customers who wanted the Kubernetes API combined with a serverless experience.
Change in our industry never happens over night. It is an evolutionary (and slow) process for many reasons.
And that is why I believe that Knative has a great chance of creating a simplified version of Kubernetes for end-users. Not as an replacement, but as a higher-level interface to hide the complexities of the Kubernetes platform.
Over the years we all learned that “Kubernetes is a platform for building platforms”. And we are seeing this happening with Knative and all the other projects leveraging the Kubernetes core to abstract and simplify3.
Look at the following picture contrasting (and highly trivialising) an application deployment (and its dependencies) on a single server vs. in a distributed environment. Kubernetes can be seen as a distributed kernel, with lots of low-level primitives to wire together the infrastructure machinery required for your application, e.g. networking and state.
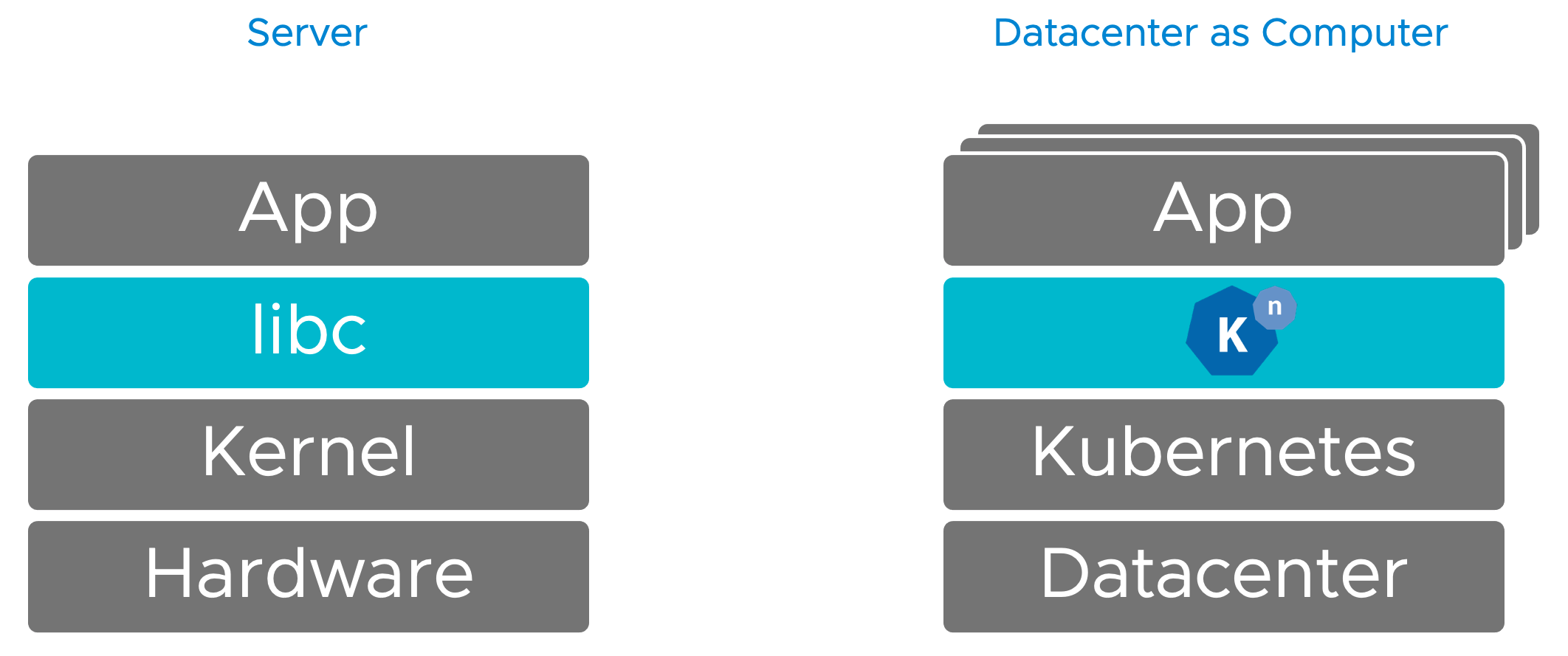
The missing link so far has been an equivalent of libc4. Libc was designed to be a simplified interface to the Linux kernel to not have to directly call and deal with syscalls. Almost every application (process), programming language (such as Java and Python) and runtime depends on it to avoid reinventing the wheel.
I had several conversations with Ahmet on Twitter back in the days, whether Knative can (should) be seen as the distributed equivalent of libc. Your mileage might vary, but I think it makes a good analogy to explain the matter 😀
And if you pay close attention to the picture above, language runtimes, e.g. Java, on both stacks are (intentionally) missing to focus on the essence.
With this simplification I also mean that Knative won’t be the end game either and we’ll see more abstractions raising on a standardized Cloud API5, including specialized frameworks for mathematical computation (AI/ML), big data processing, continuous integration and deployment, etc. The founders and community are pretty clear about the need to improve the user experience, so there’s lots of opportunity (and work) ahead.
Nevertheless, Knative gives us a great foundation on the path to serverless for the masses with open APIs, 100% conformance to industry standards like CloudEvents and extensibility in mind right from day 1.
And I’m sure that we will see a similar adoption and support from the leading cloud providers over time, as has happened to Kubernetes. Google Cloud Run is a good example of meeting the users where they are, and was recently followed by AWS announcing App Runner6.
I keep repeating myself (and the wisdom of thought leaders) here, but serverless is not a technology, but a spectrum and change in mindset.
There and back again
After our little detour above to set up the scene, let me explain why we did not use Knative as part of the VEBA project in 2019. I’ll also point out the mistakes the Knative community did in the beginning from an end-user’s, i.e. my very personal, perspective.
In early 2019, Knative had not gained much traction in the wider community for various reasons. Of course the project was still young, thus we decided using the more widely adapted (OpenFaaS) platform in VEBA.
But this was certainly not the main reason (we kept an eye on the Knative project ever since then).
Ahmet already mentioned the tight coupling between Knative and Istio which definitely was a big concern for us. Instead of integrating and maintaining the Knative components in VEBA, we would also have to understand and integrate another large code base into a resource-constrained appliance. Too much overhead and too many things that could go wrong in our user’s environments which we feared would have hurt the adoption of VEBA.
Eventually, the coupling between Istio and Knative was resolved and we took another look on the project in early 2020.
This time, I spend some time learning and trying to grok the building blocks described on the knative.dev website. And to be honest, I was just overwhelmed with the terminology and concepts thrown at me, especially in the eventing section.
The docs are very detailed around the various components, building blocks, and capabilities (like scale-to-zero and routing), but lacked an appealing punchline on why I should use this platform to simplify my day job.
Abstractions like Channels, flows, brokers and triggers and an endless list of components like the sugar controller and community adapters quickly overflowed my small brain buffer 🤯
And when I later pushed for adopting Knative inside VEBA, I had a heard time convincing my VEBA co-creator and friend William Lam and the extended VEBA community that all this complexity is worth it.
Another challenge: the serving layer is highly customizable and so it was hard to pick the right integration (ingress and networking) and adapt advanced topics like TLS and DNS in our existing (and growing) VEBA code base. More choice is not always what you want when making a decision 😀
In a nutshell, to me Knative felt very over-engineered, made by some super smart people inside Google7 and not for the average person on this planet. It looked more like an additional toolbox on the already complex Kubernetes platform to get some nice capabilities, like scale-to-zero, and building blocks for event-driven systems…paired with a steep learning curve.
Endless discussions, tweets and blogs about project ownership and governance was another concern. Since it was not clear to us how this story might end, betting on Knative could have turned out to be a dead end.
Lastly, and perhaps most importantly Knative seemed to be targeted towards developers. As of writing, it’s even on the front matter:
Well, you could argue what defines a “developer”. But if I ask the primary VEBA persona, i.e. vSphere admins, architects and infrastructure operators, most of them would definitely not consider themselves “developers”8.
An important lesson in life is: Words matter. The Knative team definitely did not have bad intentions by focusing on the “developer” persona. Not at all! I guess they were just a bit blind on the potential this platform brings to infrastructure teams alike. At least the wording on the website did not reflect it.
Contrast this with AWS. Werner Vogels, CTO at AWS, had a famous punchline during a re:invent keynote (2017), which to me reads very inclusive to all personas.

And if you look at the use cases for AWS Lambda and related serverless components, many of them solve operational concerns, e.g. systems integration, auditing, custom autoscaling, etc.
We are witnessing the same effect in the VEBA project. After migrating the core
to Knative earlier this year, we put a lot of effort to simplify the consumption
of Knative for our target persona (here VI admins), e.g. by providing an
integrated
UI,
function
templates
and SDKs for the programming
(scripting) language of their choice (PowerShell/PowerCLI). The adoption and
feedback from a community, which in 90% of the cases has never touched git or
Docker before, has been beyond our imagination.
Our key learning was to hide, abstract and simplify the internals of Kubernetes, Knative, et al. and get out of the way of the end-user as much as possible.
Outlook: Bullish 🐮
Overall, I think Knative has a bright future. Following are some of the main reasons and signs why I think Knative will become the de facto API for software development and deployment frameworks in the Kubernetes ecosystem. These also led us to finally bet on Knative in VEBA.
First, an increasing number of users asking for Knative support showing that the Knative user base is healthy and growing.
Second, requirements around support for different messaging subsystems, durability and delivery guarantees, event trigger filters, etc. are satisfied by Knative out of the box.
Third, as we realized that we are in the business of building a platform (VEBA), standing on the shoulders of brilliant minds is never a bad thing. This goes back to avoiding to reinvent the wheel and roll our own bespoke solution. Never underestimate the complexity of building something and thrive for use vs. build.
Of course, for us this meant becoming more familiar with the Knative concepts and building blocks. But the learning curve paid of as we’re piggybacking on a strong foundation towards a serverless9 experience for our target audience. It is a false belief that vSphere admins want to learn the internals of Kubernetes or Knative to get their job done, which is getting more complex every day too.
Fourth, the Knative community has a good example to learn from (Kubernetes) and avoid mistakes from the past (incl. its very own as highlighted by Ahmet).
Fifth, more vendors and cloud/service providers are realizing that the Kubernetes API is too low-level and are using Knative’s primitives to provide a better user experience. This creates a self-enforcing feedback cycle for incremental innovation.
Sixth, and perhaps the biggest reason: customers have fully bought into AWS' serverless vision but want (need) it everywhere10. Lambda and the rediscovery of event-oriented integration patterns creates even more demand for open and extensible platforms with a sophisticated eventing core.
Is Knative for me (you)?
If you made it until here, you might be wondering whether Knative is for you. Do not blindly put your money on me, because that is a question only you can answer 😄
The following advice is what I’d tell my younger self:
Evaluate the platform, abstraction-level and consumption model that is right for your business and spend your limited innovation tokens wisely.
Unless you are in the business of a platform builder/provider, avoid the DIY11 trap and shift the heavy lifting to a vendor or a managed service provider you trust.
Use the (existing) technology that gets out of your way so you can get your work done as quick and easy as possible.
And last but not least, remember its always a team decision and (soft) factors like existing skillset, people (emotions) and processes must be equally considered during a decision.
-
For the record, I’m convinced that AWS EventBridge, somewhat silently announced in 2019, is on track the next revolution. This book, not specific to EventBridge, from James Urquhart underlines my thinking. ↩︎
-
Google App Engine and the initial version of Azure (remember Red Dog?) both in 2008. ↩︎
-
Let’s not debate whether this is actually simplifying things. Assume someone provides these APIs (interfaces) for you in a fully-managed way and you’re only consuming them. You don’t have to be a kernel expert to run Microsoft word, right? ↩︎
-
Or similar approaches in non-Linux environments. ↩︎
-
Kubernetes. ↩︎
-
While Google Cloud run promises Knative API compatibility, App Runner currently does not support the Knative APIs. Let’s see… ↩︎
-
I can attest that the Knative founders are damn smart - but nevertheless very humble, funny and kind persons! Goes back to avoiding to reinvent the wheel and roll our own bespoke solution. Never underestimate the complexity of building something and thrive for use vs. build. ↩︎
-
My colleague David pointed out that this wording actually addresses operators so they can deploy a platform with a better user experience for their developers. My point is though that operators should not only deliver Knative but also consume it for their daily work. ↩︎
-
Again, just deploying Knative or VEBA does not mean you’re serverless. Let’s imagine someone solved this for our target persona, e.g. as a managed service with serverless characteristics. ↩︎
-
For many known and good reasons, e.g. you need to support multiple cloud environments as your go-to-market strategy, legal and compliance reasons, on-premises estate, etc. ↩︎
-
Do it yourself ↩︎