12 Fractured Apps (Reloaded)
While on the road this week I was lucky to spend a lot of time with customers, all perfectly organized by my good friends Moises and Jesus from VMware Spain. I want to share one particular customer discussion with you which I think is a good learning for all of us in the container space.
“We cannot solve our problems with the same thinking we used when we created them.”
(Albert Einstein)
One customer told me about a problem he was facing when containerizing a JBoss application. The architecture at a very high level looked like this:
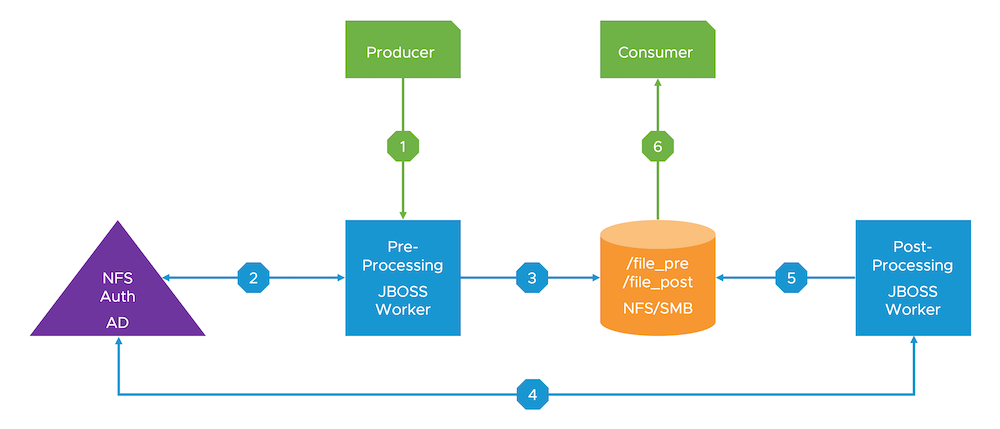
The workflow can be described as follows:
- A business “producer” sends data to a pre-processor (JBoss on Linux)
- A JBoss “pre-processor” instance processes the item and acquires a Kerberos token from Active Directory to authenticate the Linux user against the NFS server via PAM
- After successful authentication the file is saved on the NFS server
- A JBoss “post-processor”, also using Kerberos auth, periodically polls this NFS share for new pre-processed files to perform additional steps
- The output from the “post-processor” is also saved to NFS
- A business “consumer” periodically scans the NFS server for new post-processed files (Kerberos authentication omitted here as it’s not relevant for our discussion)
You might already spot several challenges here, but this communicate by sharing memory architecture is still pretty common in the enterprise. And it has worked well for many years, so we shouldn’t blame the architects. However, as demand from the business for this service increased, the IT architecture team wanted to containerize the JBoss instances to leverage all the benefits of containers and container orchestration (in this case Kubernetes). E.g. faster deployments, application isolation, increased host utilization (binpacking), automatic scaling and health checking, minimize operational overhead at the OS level (installation, patching, configuration), etc.
The customer told me about the challenges to properly get NFS and Kerberos running when the JBoss instances were instantiated as containers. Besides the fact to get an NFS client properly set up in the container (packaging, kernel modules, permissions), they also had trouble with UID/GID mappings (which can be very dynamic), Kerberos authentication and PAM on a host that could potentially run multiple JBoss instances now.
To overcome these problems in the container world, they were thinking about statically injecting UIDs/GIDs, HostPath mounts, taints and tolerations (to just run one JBoss instance on each kubelet), etc. None of them really worked, being hard to implement (scripts) or had several security flaws.
This whole discussion reminded me of an article Kelsey Hightower wrote in 2015: 12 Fractured Apps. If you haven’t read it, please do so. It basically comes down to first trying to solve the problem of containerizing a “legacy” application with scripting magic around the container. And then Albert ehm Kelsey explains how to do it right: Fix the app by following the best practices in the Twelve-Factor App Manifesto:
After I showed them Kelsey’s article, they were pretty open to other solutions. So we talked about decoupling the JBoss instances from the shared storage system by taking an event-driven approach. Fortunately the architects knew of this architectural pattern and we came up with a simple, yet elegant solution for the problem.
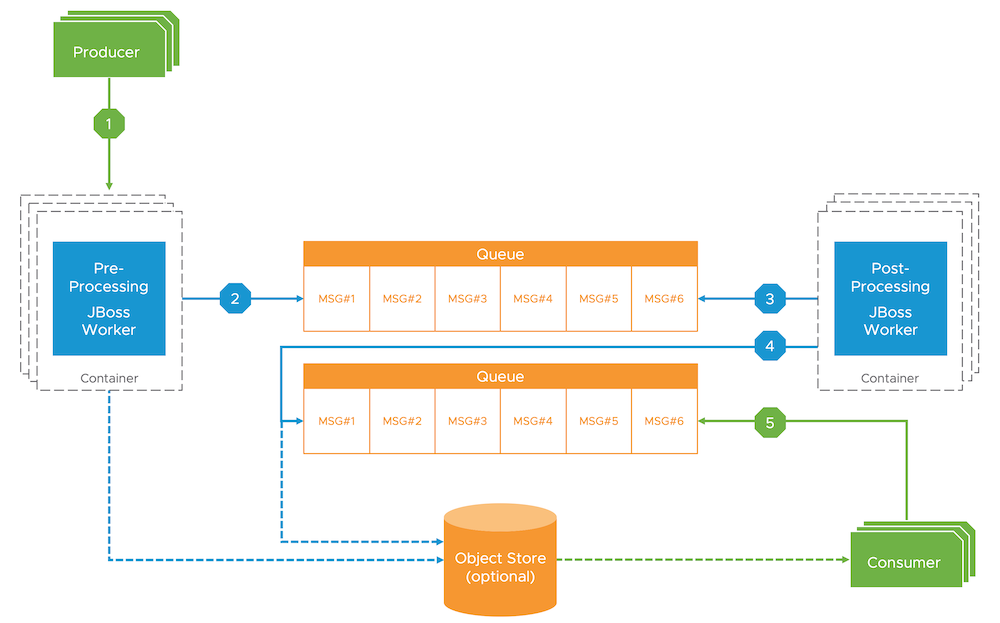
Again, the workflow can be described as follows:
- Business “producers” send data to an automatically scaled (Kubernetes) pool of pre-processors (JBoss on Linux)
- A JBoss instance processes the item and submits it to a pre-processing queue
- A pool of automatically scaled (Kubernetes) post-processors (JBoss) polls this queue for new items and processes them (1:1)
- Results are submitted to a post-processing queue
- Business consumers only poll this (post-processing) queue for new items
- Optional: depending on the message/payload size, an external object store can be used (including fine-grained identity and access management) when the size of your messages exceeds the maximum transmission size.
The customer immediately understood the benefits of this approach:
- Everything is based on standard TCP/IP communication (mostly HTTP/TLS), i.e. no ugly hacks to get NFS and Kerberos working in the container
- The design allows for horizontal scaling (pre/post-processors, queues, producers/consumers) since we’re preventing locking issues which are intrinsic to shared storage environments like NFS/SMB
- The design can be applied in almost any environment (cloud/on-premises) as it’s based on fully decoupled and standardized building blocks (portability)
- Most importantly, no NFS/Kerberos needed so now it’s easy to containerize the JBoss instances!
I know, I know. Some of you might be screaming: “YOU COPYCAT! THIS LOOKS LIKE SERVERLESS AND AWS LAMBDA!”.
Well, the customer still operates this environment (on-premises) and the JBoss processors are rather corse-grained as they contain a lot of business logic per instance. So no, it’s not (serverless) Lambda 😉. But basically you’re right. It fully embraces event-driven design and could be easily modeled with more fine-grained actors, i.e. Functions-as-a-Service. Full credit to the visionary folks at AWS making this mainstream (and my former colleague Massimo for consantly trolling me).
Of course, it goes without saying that I gave this customer my usual pitch on OpenFaaS to move into that direction. Kubernetes would be the underlying technology to run the various building blocks, e.g. queues, OpenFaaS and so on. Alex, my colleague and founder of OpenFaaS, is already invited for a follow-up.
What I really enjoyed during this workshop was the shining eyes of the architects when they realized the potential of this completely different approach to their NFS problem. They immediately identified other areas where this can be applied, for example to replace several hundred mostly idling (and expensive) Java EE instances in their environment.
Hope you enjoyed the short read as I did this customer engagement.