Events, the DNA of Kubernetes

Understanding the various components and overall system design of Kubernetes is not an easy task. This is partially due to the designers of Kubernetes fully embracing a microservices based architecture. I.e. every piece of the control (“masters”) and data plane (“nodes/workers”) is implemented as distinct services (controllers). Major advantages of this architecture are flexibility and independence in development/deployment, horizontal scalability and failure tolerance, i.e. running two or more (typically n+1) instances of critical processes like etcd, scheduler, API server, etc.
The following diagram from the Kubernetes docs shows the various components. You can read more about that here.
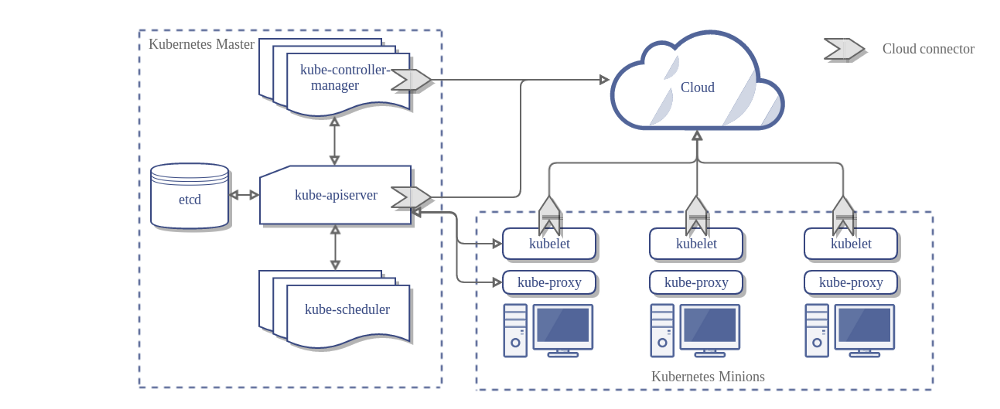
The downside is that such a microservices based architecture always comes with a steep learning curve. But this knowledge is critical for both, developers and operators, maintaining Kubernetes or developing workloads on top of it. It’s a distributed system par excellence. In my engagements with customers, colleagues and with the community I dedicate a lot of time going into the details of how Kubernetes works. Because across the board, there is often confusion or misunderstanding of the architecture, opening the door for unnecessary discussions or, even worse, failure.
“If you cannot explain something in simple terms, you don’t understand it.”
(Richard Feynman)
I realized that just by describing the individual components and adding some buzzword-magic like “choreography”, “controllers”, “stateless” and “leader election” does not always make it easier to understand what’s going on and how Kubernetes delivers on the aforementioned promises of a microservices based design.
If I would have to describe Kubernetes in one sentence it would be:
“Autonomous processes reacting to events from the API server”
These processes are modeled as control loops (observe->analyze->act1 2) and only communicate with the API server, i.e. never directly with each other. An event is simply an immutable fact that happened, e.g. “pod created”. This is also referred to as event-driven architecture3 where the flow between the individual components (microservices) is a choreography without a central orchestrator.
While working on another (long overdue) blog post I had to create an event-workflow diagram, using the Kubernetes Horizontal Pod Autoscaler4. In order to not let wait my followers, I did a short tweet on how I think of and explain Kubernetes. Dear lord, did that thing go viral! It certainly hit a nerve.
I see a lot of people having problems to understand how the Kubernetes platform works at the fundamental level, e.g. resiliency and behaviour. If you start thinking about Kubernetes as a fully event-driven system, there's answers to so many "Why"'s pic.twitter.com/fwPO9XX7zk
— Michael Gasch 🇩🇪🇺🇦 (@embano1) November 27, 2018
Many of you have asked for a blog post (and even Kubecon talk!) on this. So here’s what I wrote in a more readable and Google Search friendly way.
How I understand Kubernetes
Think of the API server as a broker with multiple immutable (replicated) logs (or queues)5, each representing a stream of events. Events are facts that can be causally related (happened-before) or not related at all (then we say they happened concurrently). etcd is important for the durability of events, but an implementation detail.
All processes (controllers), e.g. the scheduler, deployment controller, endpoint controller, Kubelet, etc. can be understood as producers and/or consumers of events from these logs (consumers can be producers as well, and vice versa).
Consumers specify the objects (and optionally namespace) they want to receive events from the API server. This is called a ListWatch in Kubernetes: list all events from the API server when the consumer starts, then switch to “watch mode” (triggered by new events) to reduce the load on the API server. Think of the combination of object+namespace as a dedicated (virtual) event queue the API server handles. As each event carries a resource version for the particular object it contains, e.g. a pod object, going back in time (time travel) is actually possible by requesting a specific resource version (and not seldom the cause of tricky bugs in Kubernetes6).
Consumers and producers don’t know about each other as they’re fully decoupled (by the queue) and autonomous. This makes the whole system extremely scalable, robust and extensible (adaptable to change).
Thus, by design, it’s a fully asynchronous and eventually consistent platform. Information takes time to propagate from producers(s) to consumers(s). The diagram below shows this where the Horizontal Pod Autoscaler hasn’t caught up with the events coming from the metrics server, which also affects the downstream chain of producers and consumers in our example.
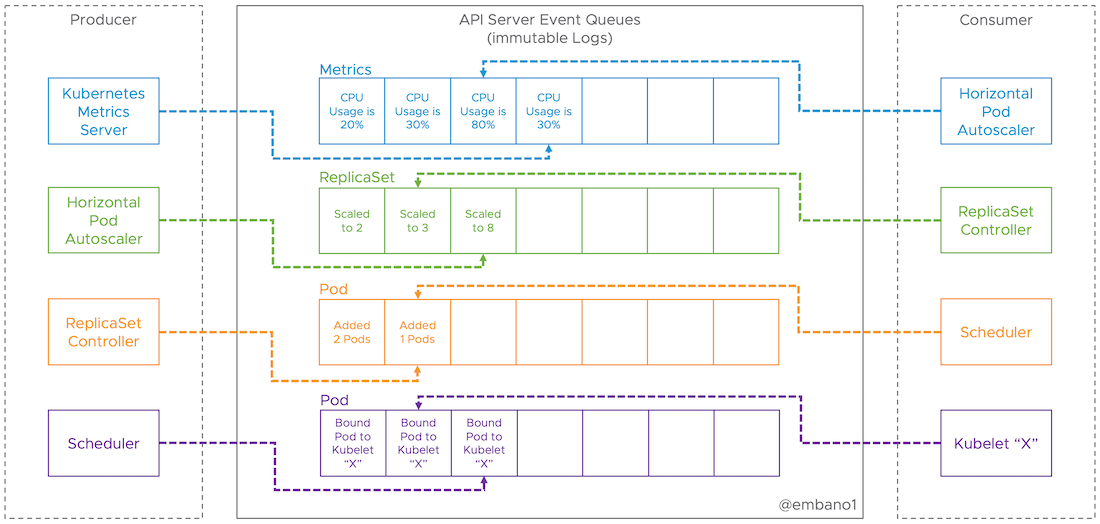
There’s NO guarantee that the system will converge to the desired state (even if you got an “OK”/ACK from the control plane). For example:
|
|
If the control plane is running fine, you’ll get a HTTP 200 return code, i.e. “OK”, even though there is no remaining capacity in the cluster7. Marko Luksa put together another great example8 of some unwanted race conditions between controllers when scaling down services.
Controllers essentially are stateless even though they perform stateful operations, e.g. the scheduler which tracks and recalculates node capacity on every pod scheduled. For efficiency and speed, received events are placed in in-memory caches or local queues in each controller. But what happens to our (local) state if a controller crashes as it does not persist state locally?
Persistency in the controller is not needed! The event-driven design will replay all (appropriate) events when the controller (re)starts, similar to the concept of event-sourcing9,10. This property is also very useful as events from the API server are delivered at most once, i.e. could be lost during transmission. Another intrinsic property for increased robustness: Kubernetes is said to be level-triggered. If an event gets lost during transmission (e.g. network issue) or your controller misses events during downtime, the next time there’s a (re-)sync it’s going to receive the complete desired state for that object from the API server. I described how reconciliation works in the scheduler here.
Since information can get delivered more than once (e.g. after failure, re-sync, etc.) and controllers don’t talk to each other directly, there’s a potential for race conditions when state is to be changed, e.g. a write to same object from different controllers. This is called optimistic concurrency and needs to be handled in the application layer (i.e. in each controller logic). Idempotency and compare and set with retries (based on monotonically increasing resource versions) are patterns used to address this11.
Event-driven design has many more advantages and can address a lot of problems in distributed systems, most importantly temporal and spatial decoupling with queuing/buffering, applying back-pressure, event replay for auditing/debugging, etc. However, it’s not a new idea. Not at all! For example, relational databases work the same way (transaction log). The database is said to be the (stale) cache of the immutable log 😄 . If you want to learn more about event-driven design, make sure to check out this video from Jonas Boner.
Building systems using events as a first class citizen is not specific to computer science. Events are the reason for all being. Without events, there would be no change! What is time anyways? Think about it, it’s an applied and battle-tested design in nature and can easily become a very long philosophical discussion…For the curious in you take a look at the Closer to Truth science channel on Youtube.
Btw: Stefan Schimanski and Michael Hausenblas have written a great series of how the API server actually is implemented. Remember: I was describing a thought model for a better understanding.
I was so happy to see all the great responses from the community and never thought of how this tweet could reach almost 100k people (according to Twitter stats) in less than a week. Thank you!
Ok now I understand Kubernetes! https://t.co/PhHzmExoA6
— Hélène Longuet Caraux - Digression Photo (@LNbzzz) November 30, 2018
-
OODA loop: https://en.wikipedia.org/wiki/OODA_loop ↩︎
-
The Kubernetes Control Plane for Busy People Who Like Pictures - Daniel Smith, Google: https://www.youtube.com/watch?v=zCXiXKMqnuE ↩︎
-
What do you mean by “Event-Driven”?: https://martinfowler.com/articles/201701-event-driven.html ↩︎
-
Horizontal Pod Autoscaler: https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/ ↩︎
-
I’m using “log” and “queue” interchangeably here, which technically is not correct. Since I’m describing a thought model here, let’s not debate. The main difference is that a log allows time travel by keeping the messages until they’re garbage collected, e.g. by log compaction. The Kubernetes API server as of writing this post has a default of 5 minutes (configurable) after it triggers an etcd compaction and older versions of an object are discarded. You can read about the differences in this legendary article from Jay Kreps. ↩︎
-
Kubernetes is vulnerable to stale reads, violating critical pod safety guarantees: https://github.com/kubernetes/kubernetes/issues/59848 ↩︎
-
A HTTP return code of 201 / 202 (created/accepted) semantically would be more correct and thus this behavior is considered a bug in Kubernetes: https://twitter.com/bgrant0607/status/1121085412921884672?s=20 ↩︎
-
Handling Client Requests Properly with Kubernetes: https://freecontent.manning.com/handling-client-requests-properly-with-kubernetes/ ↩︎
-
Event Sourcing: https://martinfowler.com/eaaDev/EventSourcing.html ↩︎
-
Well, the ListWatch performed during controller initialization will usually pick up the latest state of an object the corresponding API server has in cache (depending on the resource version passed in initially, see Kubernetes API docs) and thus not fully replay all available (not compacted) resource versions. But as already described, knowing the resource version it is possible to replay a stream of events for an object (until compacted). ↩︎
-
Writing Controllers: https://github.com/kubernetes/community/blob/master/contributors/devel/sig-api-machinery/controllers.md ↩︎